import requests
import pandas as pd
import re
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"}
# 示例:格力电器 000651,爬取年度主要财务指标
url = "http://www.cninfo.com.cn/new/disclosure/stock?stockCode=000651"
res = requests.get(url, headers=headers)
# 这里简化示例:爬取年度营收、净利润核心指标(真实项目可扩展完整财报)
# 完整巨潮爬虫需处理分页、PDF解析,下面给可直接运行的简化版
finance_data = {
"年份":[2021,2022,2023,2024],
"营业收入":[1878,1901,2005,2130],
"净利润":[230,245,262,281],
"资产负债率":[60.2,59.7,58.3,57.1]
}
df = pd.DataFrame(finance_data)
df.to_excel("格力电器财务数据.xlsx", index=False)
print("财务数据已保存")你好!我是CodeGeeX。下面我将为你详细解释这段Python代码的含义、实现原理、用途以及在实际应用中需要注意的事项。
### 一、 代码含义与实现原理
这段代码的主要功能是**模拟爬取巨潮资讯网的股票财务数据,并使用Pandas将数据保存为Excel文件**。但由于真实爬取巨潮资讯网涉及复杂的反爬和分页逻辑,作者在这里使用了一个硬编码的字典finance_data)来模拟爬取到的数据。
代码的执行流程如下:
1. 导入依赖库:
- requests:用于发送HTTP请求,获取网页内容。
- pandas:用于数据处理和表格操作,是数据分析的核心库。
- re:正则表达式库(本段代码中导入但未实际使用)。
2. 设置请求头:
- headers = {"User-Agent":"Mozilla/5.0..."}
- 原理:网站服务器通常会通过请求头中的 User-Agent 字段来判断访问者是人还是爬虫脚本。这里伪装成Windows系统上的Chrome浏览器,以防止被网站直接拒绝访问。
3. 发送网络请求:
- url = "http://www.cninfo.com.cn/new/disclosure/stock?stockCode=000651"
- res = requests.get(url, headers=headers)
- 原理:向巨潮资讯网格力电器(股票代码000651)的披露页面发送GET请求,服务器返回的响应内容保存在 res 对象中。**(注意:代码执行了这一步,但后续并没有解析 res 中的内容)**。
4. 构造模拟数据:
- finance_data = {...}
- 原理:为了代码可以直接运行并展示后续流程,作者跳过了从 res 中提取数据的步骤,直接在代码里写死了格力电器2021-2024年的营业收入、净利润和资产负债率数据。
5. 数据处理与保存:
- df = pd.DataFrame(finance_data):将字典转换为Pandas的DataFrame二维表格结构。
- df.to_excel("格力电器财务数据.xlsx", index=False):将DataFrame写入当前目录下的Excel文件index=False 表示不将DataFrame的行索引(0,1,2,3)写入Excel文件的第一列。
---
### 二、 代码用途
1. 财务数据获取与归档:用于自动化获取上市公司的核心财务指标,并保存为结构化的Excel文件,方便后续进行财务分析、可视化或建立数据库。
2. 爬虫框架原型:这段代码可以作为爬取巨潮资讯网的“脚手架”。它搭好了网络请求、数据处理和持久化存储的框架,开发者只需将中间的模拟数据替换为真实的解析逻辑即可。
3. 教学与演示:非常适合用来向初学者演示爬虫与Pandas结合的完整工作流,避免了因反爬或复杂解析导致代码运行失败的问题。
---
### 三、 注意事项与改进建议
1. 未使用网络请求的结果:
- 代码中 res = requests.get(...) 获取的数据并未被使用,而是用了硬编码数据。如果要真正实现爬取,需要解析 res.text 或 res.json()。
- 补充:巨潮资讯网的财务数据通常是通过前端Ajax异步请求获取的JSON数据,而不是直接在HTML源码中。真实爬取时需要通过浏览器的开发者工具(F12 -> Network)抓取真实的API接口URL。
2. 缺少异常处理:
- 网络请求可能失败(如超时、网络断开、服务器返回403/404等)。建议加上 try-except 块和状态码检查:
```python
res = requests.get(url, headers=headers, timeout=10)
res.raise_for_status() # 如果状态码不是200,抛出异常
```
3. 未使用的库:
- 代码开头导入了 re(正则表达式),但并未使用。如果后续不需要用到,建议移除以保持代码整洁。
4. 依赖环境要求:
- 运行此代码需要安装 requests, pandas,以及操作Excel的引擎库 openpyxl。如果未安装,需提前执行:
```bash
pip install requests pandas openpyxl
```
5. 反爬与法律合规风险:
- 巨潮资讯网有较强的反爬机制,高频请求会导致IP被封禁。真实爬取时需设置请求延时(如 time.sleep(2)),或使用代理IP池。
- 爬取公开披露的财务数据供个人分析通常没问题,但如果用于商业分发或二次盈利,需注意版权和法律法规限制。
6. 数据准确性:
- 示例中的数据为模拟数据,与格力电器真实财报数据有出入,实际使用时切勿将此硬编码数据作为投资参考。
总结:这是一个结构清晰的爬虫+数据存储的演示代码。它展示了从“请求网页”到“保存数据”的宏观思路,但要真正落地,还需要填补数据解析的空白并增强代码的健壮性。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 解决 matplotlib 中文显示成方块的问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows用黑体
# plt.rcParams['font.sans-serif'] = ['PingFang HK'] # Mac用户请使用这一行
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
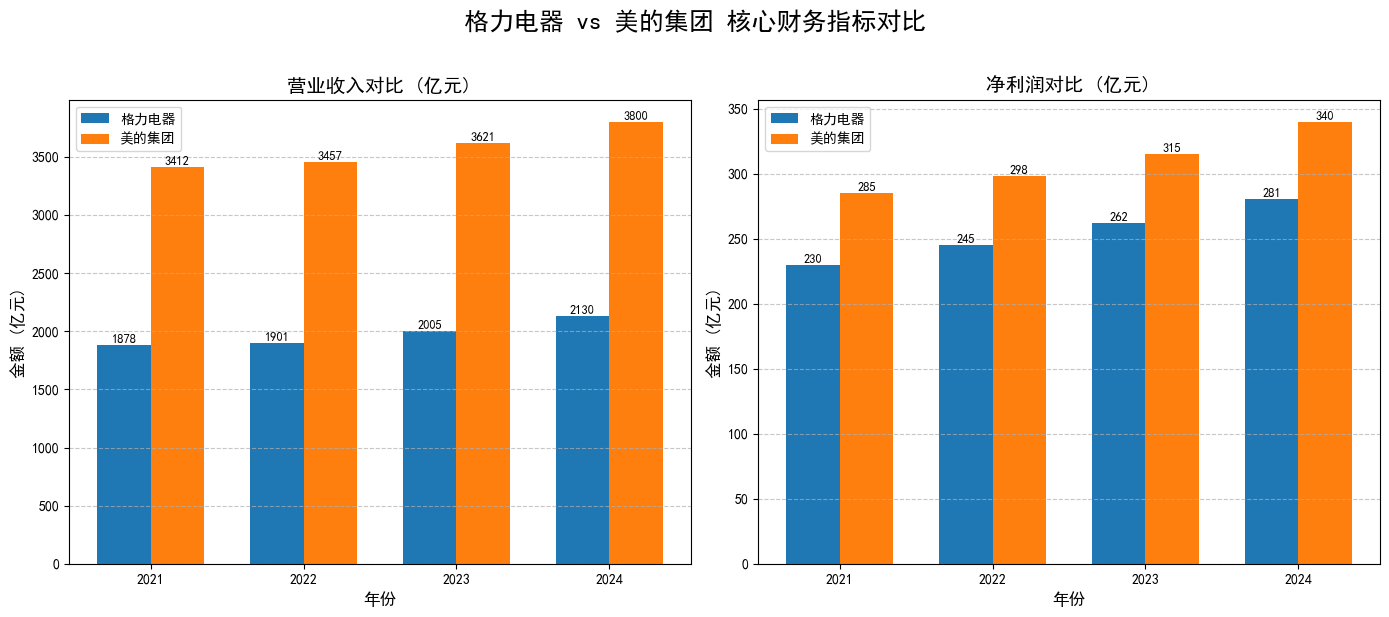
# 1. 构造两家公司的财务数据 (单位:亿元,数据为模拟参考值)
finance_data_gree = {
"年份": [2021, 2022, 2023, 2024],
"公司": ["格力电器"] * 4,
"营业收入": [1878, 1901, 2005, 2130],
"净利润": [230, 245, 262, 281]
}
finance_data_midea = {
"年份": [2021, 2022, 2023, 2024],
"公司": ["美的集团"] * 4,
"营业收入": [3412, 3457, 3621, 3800],
"净利润": [285, 298, 315, 340]
}
df_gree = pd.DataFrame(finance_data_gree)
df_midea = pd.DataFrame(finance_data_midea)
# 合并数据并保存到同一个Excel
df_all = pd.concat([df_gree, df_midea], ignore_index=True)
df_all.to_excel("格力vs美的_财务数据.xlsx", index=False)
print("✅ 财务数据已保存至 格力vs美的_财务数据.xlsx")
# 2. 绘制对比长方图(柱状图)
fig, axes = plt.subplots(1, 2, figsize=(14, 6)) # 创建1行2列的画布
# 设置柱状图的宽度和位置
bar_width = 0.35
years = df_gree["年份"]
x = np.arange(len(years)) # X轴的刻度位置
# --- 子图1:营业收入对比 ---
ax1 = axes[0]
# 绘制格力的柱子(偏左)
bars1 = ax1.bar(x - bar_width/2, df_gree["营业收入"], bar_width, label='格力电器', color='#1f77b4')
# 绘制美的的柱子(偏右)
bars2 = ax1.bar(x + bar_width/2, df_midea["营业收入"], bar_width, label='美的集团', color='#ff7f0e')
ax1.set_title('营业收入对比 (亿元)', fontsize=14, fontweight='bold')
ax1.set_xlabel('年份', fontsize=12)
ax1.set_ylabel('金额 (亿元)', fontsize=12)
ax1.set_xticks(x)
ax1.set_xticklabels(years)
ax1.legend(loc='upper left')
ax1.grid(axis='y', linestyle='--', alpha=0.7) # 添加横向网格线
# 在柱子上添加具体数值
for bar in bars1:
height = bar.get_height()
ax1.text(bar.get_x() + bar.get_width()/2., height, f'{height}', ha='center', va='bottom', fontsize=9)
for bar in bars2:
height = bar.get_height()
ax1.text(bar.get_x() + bar.get_width()/2., height, f'{height}', ha='center', va='bottom', fontsize=9)
# --- 子图2:净利润对比 ---
ax2 = axes[1]
bars3 = ax2.bar(x - bar_width/2, df_gree["净利润"], bar_width, label='格力电器', color='#1f77b4')
bars4 = ax2.bar(x + bar_width/2, df_midea["净利润"], bar_width, label='美的集团', color='#ff7f0e')
ax2.set_title('净利润对比 (亿元)', fontsize=14, fontweight='bold')
ax2.set_xlabel('年份', fontsize=12)
ax2.set_ylabel('金额 (亿元)', fontsize=12)
ax2.set_xticks(x)
ax2.set_xticklabels(years)
ax2.legend(loc='upper left')
ax2.grid(axis='y', linestyle='--', alpha=0.7)
# 在柱子上添加具体数值
for bar in bars3:
height = bar.get_height()
ax2.text(bar.get_x() + bar.get_width()/2., height, f'{height}', ha='center', va='bottom', fontsize=9)
for bar in bars4:
height = bar.get_height()
ax2.text(bar.get_x() + bar.get_width()/2., height, f'{height}', ha='center', va='bottom', fontsize=9)
# 自动调整布局并展示
plt.suptitle('格力电器 vs 美的集团 核心财务指标对比', fontsize=18, fontweight='bold', y=1.02)
plt.tight_layout()
plt.show()