import requests
from bs4 import BeautifulSoup
import pandas as pd
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"}
data = []
for page in range(0,250,25):
url = f"https://movie.douban.com/top250?start={page}&filter="
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,"html.parser")
items = soup.find_all("div",class_="item")
for i in items:
title = i.find("span",class_="title").get_text()
score = i.find("span",class_="rating_num").get_text()
info = i.find("div",class_="bd").p.get_text().strip()
data.append({"电影名":title,"评分":score,"信息":info})
df = pd.DataFrame(data)
df.to_csv("豆瓣Top250.csv",index=False,encoding="utf-8-sig")
print("爬取完成,已保存为豆瓣Top250.csv")这段代码是一个典型的**Python网络爬虫**脚本,其主要功能是**抓取豆瓣电影Top250榜单的数据,并将其保存为CSV格式的表格文件**。
下面我将从实现原理、用途和注意事项三个方面为您详细解释这段代码:
### 一、 实现原理(代码逐行解析)
代码的执行流程可以分为:发送请求获取网页源码 -> 解析源码提取数据 -> 循环翻页 -> 存储数据。
1. 导入必要的库
```python
import requests # 用于发送HTTP请求,获取网页内容
from bs4 import BeautifulSoup # 用于解析HTML文档,提取所需数据
import pandas as pd # 用于数据处理和将数据保存为CSV格式
```
2. 设置请求头和空列表
```python
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"}
data = []
```
- headers:伪装成Chrome浏览器访问。因为网站通常会拒绝直接的Python请求(requests的默认User-Agent),加上浏览器标识可以绕过基础的反爬机制。
- data:用于临时存储所有抓取到的电影信息字典。
3. 循环翻页逻辑
```python
for page in range(0, 250, 25):
```
豆瓣Top250每页显示25部电影,共10页。URL中start参数表示起始电影的索引(0, 25, 50...225)。通range(0, 250, 25)生成这10个起始值,实现自动翻页。
4. 请求与解析网页
```python
url = f"https://movie.douban.com/top250?start={page}&filter="
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, "html.parser")
items = soup.find_all("div", class_="item")
```
- 拼接出每一页的真实URL。
- requests.get()获取网页的HTML源码。
- BeautifulSoup使用Python内置html.parser解析器将源码转化为可操作的对象。
- find_all找出当前页面中所有classitemdiv标签,每一个这样div就包含了一部电影的全部信息。
5. 提取具体数据
```python
for i in items:
title = i.find("span", class_="title").get_text()
score = i.find("span", class_="rating_num").get_text()
info = i.find("div", class_="bd").p.get_text().strip()
data.append({"电影名":title, "评分":score, "信息":info})
```
在每部电影item块中:
- 寻找classtitlespan标签,获取电影名。
- 寻找classrating_numspan标签,获取评分。
- 寻找classbddiv下p标签,获取导演、演员、年份等信息,并.strip()去除首尾空白字符。
- 将提取的数据组合成字典,追加data列表中。
6. 数据存储
```python
df = pd.DataFrame(data)
df.to_csv("豆瓣Top250.csv", index=False, encoding="utf-8-sig")
```
- 使pandas将列表字典转换为DataFrame二维表结构。
- to_csv保存为CSV文件index=False表示不保存行索引encoding="utf-8-sig"指定编码为带BOM的UTF-8,这样可以防止用Excel打开中文CSV时出现乱码。
---
### 二、 用途
1. 数据获取:快速获取豆瓣高分电影榜单的结构化数据,无需手动复制粘贴。
2. 数据分析基础:获取的CSV文件可以直接导入到Excel、Tableau或Python中,用于进行电影评分分布分析、导演作品统计、年代趋势分析等数据可视化项目。
3. 学习练手:这是爬虫入门最经典的案例之一,涵盖了请求、解析、翻页、存储的完整爬虫生命周期。
---
### 三、 注意事项(非常重要)
1. 法律与合规风险:
- 豆瓣robots.txt协议是禁止爬虫抓/top250等路径的。虽然该代码仅供学习,但高频次的爬取可能会给服务器造成压力,甚至触犯相关法律法规。**请勿用于商业用途,且爬取时务必控制频率。**
2. 反爬机制导致代码可能无法直接运行:
- IP封禁:连续请求10页很容易触发豆瓣的反爬机制,导致IP被暂时封禁(返回403或重定向到验证码页面)。建议requests.get()中增time.sleep(1~3)来降低爬取速度。
- Cookie验证:豆瓣现在对Top250页面的访问越来越严格,有时仅User-Agent已经不够,可能需要headers中添加你的登Cookie才能成功访问。
3. 代码健壮性问题(容易报错):
- i.find("span", class_="title") 如果某个电影节点没有这个标签.find()会返None,此时再调.get_text()会抛AttributeError。
- 改进建议:使try...except包裹提取逻辑,或者进行判断,例如:
```python
title_tag = i.find("span", class_="title")
title = title_tag.get_text() if title_tag else "未知"
```
- 部分电影可能有多<span class="title">(中英文片名)find只会取第一个,如果需要完整的英文片名,需要find_all。
4. 数据清洗问题:
- 提取info信息包含了导演、主演、年份、国家、类型,全部挤在一个字符串里,且包含大量的换行符和空格(导演: 弗兰克·德拉邦特\n主演: 蒂姆·罗宾斯.../ 1994 / 美国 / 犯罪 剧情)。
- 直接存入CSV后,这部分数据很难直接用于分析。建议后续使用正则表达式re模块)info进行拆分,提取出独立的“年份”、“国家”、“类型”等字段。
5. 编码问题:
- 代码中使用utf-8-sig,这在Windows的Excel中打开中文是正常的。但如果在Mac的Excel中打开,可能仍会有乱码,Mac用户建议使utf-8编码,或者在导入Excel时手动指定编码格式。
生成图表:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import random
# ================= 1. 数据爬取 =================
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"}
data = []
print("正在爬取豆瓣Top250数据,请稍候...")
for page in range(0, 250, 25):
url = f"https://movie.douban.com/top250?start={page}&filter="
try:
res = requests.get(url, headers=headers, timeout=10)
soup = BeautifulSoup(res.text, "html.parser")
items = soup.find_all("div", class_="item")
for i in items:
title = i.find("span", class_="title").get_text()
score = float(i.find("span", class_="rating_num").get_text())
# 提取排名:原网页中 class="pic" 下的 em 标签包含了排名数字
rank = int(i.find("div", class_="pic").em.get_text())
data.append({"排名": rank, "电影名": title, "评分": score})
except Exception as e:
print(f"爬取第 {page} 页失败: {e}")
df = pd.DataFrame(data)
# ================= 2. 数据抽样 =================
# 将排名分为10个区间:1-25, 26-50, ..., 226-250
df['区间'] = pd.cut(df['排名'], bins=range(0, 251, 25), labels=[f"Top {i}" for i in range(1, 241, 25)])
# 每个区间随机抽取1部电影
sample_df = df.groupby('区间', group_keys=False).apply(lambda x: x.sample(1)).reset_index(drop=True)
# 按排名升序排序,保证图表从高到低显示
sample_df = sample_df.sort_values(by='排名', ascending=True)
print("\n抽样结果:")
print(sample_df[['排名', '电影名', '评分']])
# ================= 3. 绘制美观图表 =================
# 设置中文字体,防止中文显示为方块
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows用黑体
# Mac用户请注释上一行,取消注释下一行:
# plt.rcParams['font.sans-serif'] = ['PingFang HK']
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 创建画布
fig, ax = plt.subplots(figsize=(12, 7))
# 生成渐变色
colors = plt.cm.viridis(np.linspace(0.3, 0.9, len(sample_df)))
# 绘制水平条形图 (barh 更适合展示长电影名)
bars = ax.barh(
y=range(len(sample_df)),
width=sample_df['评分'],
color=colors,
height=0.6,
edgecolor='white',
linewidth=1.2
)
# 设置Y轴刻度标签为:排名 + 电影名
y_labels = [f"No.{row['排名']} {row['电影名']}" for _, row in sample_df.iterrows()]
ax.set_yticks(range(len(sample_df)))
ax.set_yticklabels(y_labels, fontsize=12, fontweight='bold')
# 在直条末端添加具体评分数字
for bar in bars:
width = bar.get_width()
ax.text(width + 0.05, bar.get_y() + bar.get_height()/2,
f'{width:.1f}', va='center', ha='left', fontsize=11, fontweight='bold', color='#333333')
# 美化图表样式
ax.set_xlim(8.0, 10.0) # 豆瓣高分电影评分集中在8-10分,截断X轴让差异更明显
ax.set_title('豆瓣电影 Top 250 区间代表评分图', fontsize=18, fontweight='bold', pad=20, color='#2c3e50')
ax.set_xlabel('豆瓣评分', fontsize=14, labelpad=10, color='#34495e')
ax.invert_yaxis() # 反转Y轴,让排名第1的在最上面
# 去除边框垃圾线,更简洁
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_color('#bdc3c7')
ax.spines['left'].set_color('#bdc3c7')
ax.tick_params(axis='x', colors='#7f8c8d')
# 添加背景网格线
ax.grid(axis='x', linestyle='--', alpha=0.3, color='#95a5a6')
plt.tight_layout()
plt.show()
print("\n图表生成完毕!")
正在爬取豆瓣Top250数据,请稍候...
抽样结果:
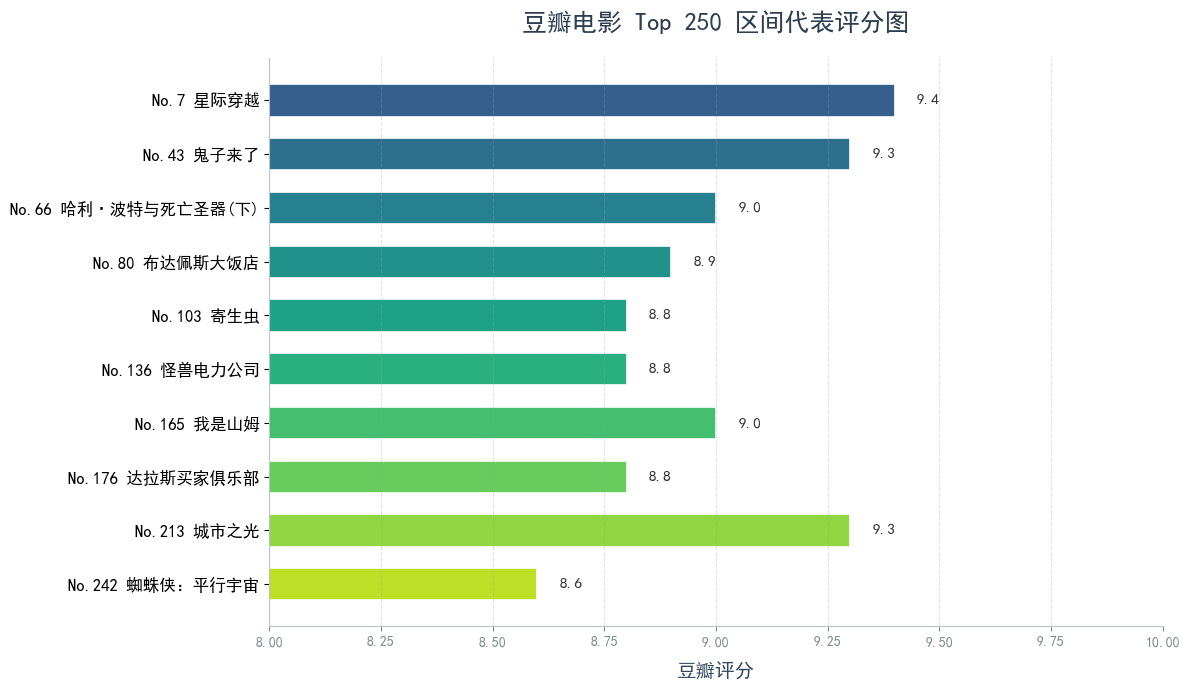
排名 电影名 评分
0 7 星际穿越 9.4
1 43 鬼子来了 9.3
2 66 哈利·波特与死亡圣器(下) 9.0
3 80 布达佩斯大饭店 8.9
4 103 寄生虫 8.8
5 136 怪兽电力公司 8.8
6 165 我是山姆 9.0
7 176 达拉斯买家俱乐部 8.8
8 213 城市之光 9.3
9 242 蜘蛛侠:平行宇宙 8.6